RAG: The Architecture That Makes Enterprise AI Actually Work
 14/04/2026
14/04/2026
What RAG Actually Does — In Plain Terms
Imagine your most knowledgeable employee. They know the business cold. But they graduated from university seven years ago and have not read a single internal document since. That is your LLM without RAG.
Now give that same person real-time access to your company’s entire document library — searchable, indexed, retrievable in milliseconds. Before they answer any question, they pull the three most relevant documents, read them, and synthesize a grounded, cited response. That is RAG.
The acronym breaks down simply: Retrieval — semantically searching your enterprise knowledge base before anything is generated. Augmented — injecting those retrieved passages into the model’s active context. Generation — producing a grounded, citable answer from real organizational data, not from approximation.
The Five-Step Mechanism — How RAG Works
Understanding the mechanism gives you the vocabulary to evaluate vendor claims, architect your own system, and diagnose failures when they occur.
Step 1: Ingestion and Chunking. Every document in your knowledge base — PDFs, SharePoint files, Salesforce records, Confluence wikis, SAP reports, ServiceNow tickets, Snowflake tables — is ingested and broken into semantically coherent chunks. Enterprise RAG uses overlapping chunks of 512–1,024 tokens with 10–20% overlap to preserve context at boundaries.
Step 2: Embedding. Each chunk is passed through an embedding model that converts text into a dense numerical vector — a mathematical representation of meaning. Similar documents produce mathematically close vectors. The result is a vector database that stores meaning, not just text.
Step 3: Query Vectorization. The user’s query is passed through the same embedding model, becoming a vector. The system now has two representations of meaning: the question, and every document chunk in your knowledge base.
Step 4: Semantic Retrieval. The vector database performs a nearest-neighbor search — finding chunks whose meaning is mathematically closest to the query. The top 3–10 results are returned in milliseconds. These are the most semantically relevant passages from your knowledge base.
Step 5: Augmented Generation. Retrieved chunks are assembled into a structured prompt alongside the user’s question. The model reads the retrieved documents, reasons over them, and generates a grounded response with source attribution. It cannot confabulate facts that are not in the retrieved context.
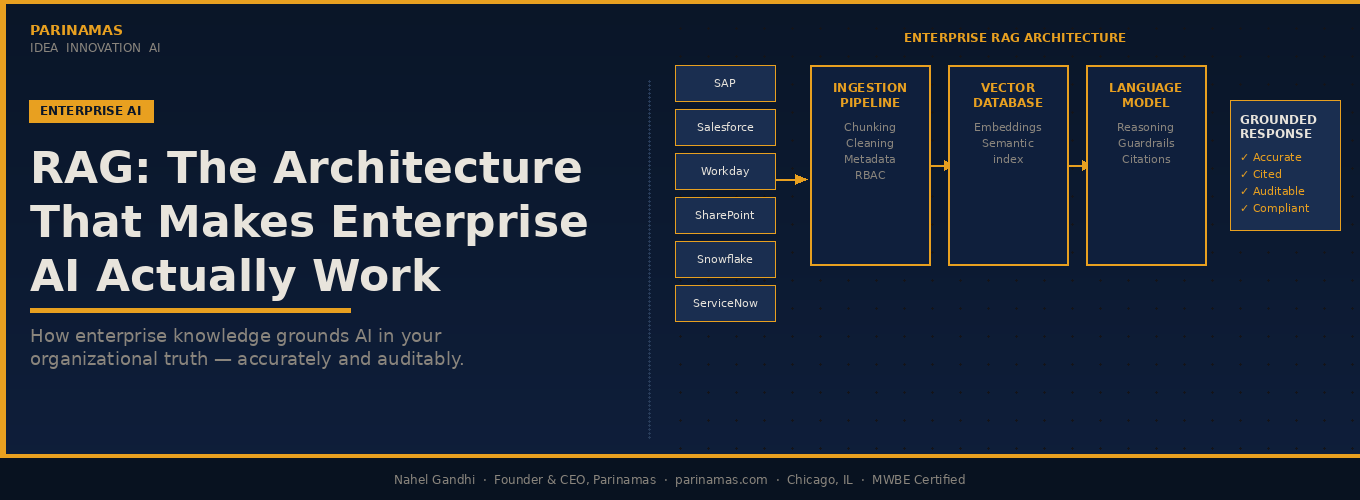
The Enterprise RAG Architecture
Consumer RAG connects a few PDFs to a model. Enterprise RAG federates retrieval across every major organizational system — enforcing access control, maintaining freshness, and operating at production scale.
ENTERPRISE RAG ARCHITECTURE
SOURCES
INGESTION
PIPELINE
Chunking
Cleaning
Metadata tagging
Access control
VECTOR
DATABASE
Embeddings
Semantic index
RBAC enforced
ANN retrieval
LANGUAGE
MODEL
Augmented ctx
Reasoning
Guardrails
Source citations
GROUNDED
RESPONSE
Accurate
Cited sources
Auditable
Compliant
Nahel | Parinamas | parinamas.com · Chicago · MWBE
The architecture above is not theoretical — it is the production pattern we implement for enterprise clients. Every source system connects through an ingestion pipeline that handles chunking, cleaning, metadata tagging, and access control labeling. The vector database enforces role-based access at retrieval time. The language model operates on pre-screened, authorized context only.
Enterprise RAG vs. Basic RAG: The Critical Distinctions
Scale of the knowledge base. Consumer RAG operates over hundreds of documents. Enterprise RAG operates over millions of records, updated continuously. Your ingestion pipeline must handle SAP change events, Salesforce record updates, and SharePoint document revisions in near real-time. In financial services, a policy document 48 hours out of date can create regulatory exposure.
Access control at retrieval, not the application layer. Enterprise knowledge is not uniformly accessible. Enterprise RAG must enforce document-level security in the vector database itself — integrated with your identity provider — not applied as a filter after retrieval has already occurred.
Multi-source federation. Enterprise knowledge lives in SAP, Salesforce, Workday, SharePoint, Confluence, ServiceNow, and Snowflake simultaneously. Enterprise RAG requires federated retrieval — pulling from multiple vector stores in parallel, ranking results across sources, synthesizing a coherent answer.
Hallucination containment. Enterprise RAG implements faithfulness scoring, source attribution, and confidence thresholds — if no documents exceed a similarity threshold, the system says “I don’t have enough information” rather than fabricating.
Latency requirements. Optimized enterprise RAG operates end-to-end — retrieval plus generation — in 2 to 4 seconds. This requires caching layers, pre-computed embeddings, approximate nearest-neighbor indexes (HNSW, IVF), and model quantization for inference.
RAG vs. Fine-Tuning: The Decision Framework
Use RAG when: Your knowledge changes frequently. You need citeable, auditable answers. Your data is proprietary and sensitive. You want to launch in weeks, not months. The facts matter more than the style of expression.
Use fine-tuning when: You need to change how the model behaves, not what it knows. You are teaching specialized domain vocabulary. You have a large, stable, curated training dataset.
Use both when: You need domain-adapted reasoning applied to current, proprietary information. A fine-tuned model understanding your industry vocabulary combined with a RAG layer providing current organizational knowledge is the state-of-the-art architecture for complex enterprise deployments. This is the pattern behind our highest-ROI client engagements.
The practical reality: most enterprise use cases are answered by RAG alone, implemented well. Fine-tuning adds cost, complexity, and maintenance overhead. Start with RAG. Add fine-tuning only when you have identified a specific behavioral gap that retrieval cannot solve.
Enterprise Use Cases by Vertical
Financial Services. Relationship managers query client history, risk profiles, and portfolio performance across Salesforce, Bloomberg feeds, and internal research simultaneously. Compliance teams ask questions about current regulatory requirements and get answers traced to specific regulations. Credit analysts retrieve covenant documentation and precedent transactions in seconds rather than hours.
Manufacturing and Operations. Technicians query maintenance manuals, failure history, and parts availability in natural language. Quality teams retrieve inspection records and non-conformance reports across facilities. Supply chain managers ask about supplier performance across contracts, invoices, and quality data — a pattern central to the 547% ROI we delivered for a manufacturing client.
Logistics and Supply Chain. Dispatchers retrieve carrier agreements, lane performance data, and claims history instantly. Procurement teams analyze supplier contracts across jurisdictions. Operations leadership queries real-time shipment data alongside historical performance benchmarks.
Retail and Consumer. Category managers retrieve competitive intelligence, trend data, and historical performance simultaneously. Merchants query planogram compliance and promotional performance across stores. Customer service teams access complete customer history, product documentation, and return policies in a single interface.
Food and Beverage. Quality assurance teams retrieve supplier certifications, audit histories, and regulatory requirements by product and ingredient. R&D teams query formulation databases, regulatory filings, and consumer research simultaneously.
The Business Value of Getting This Right
ENTERPRISE RAG — BUSINESS VALUE
The ROI drivers we have measured consistently across enterprise RAG deployments: knowledge workers spend 20–35% of their working time searching for information. In a 200-person organization at a fully-loaded cost of $100K per employee, that is $4–7M per year in unproductive search time. A mature RAG system that reduces search time by 60% delivers $2.4–4.2M in recovered productivity annually — before accounting for decision latency reduction, error reduction, and the capacity for growth without proportional headcount increase.
The Data Governance Imperative
Access control must be enforced at retrieval, not at the application layer. If your RAG system retrieves documents and then filters the response, you have already exposed the data to the model. Proper enterprise RAG enforces access control in the vector database — retrieval only returns documents the querying user has permission to see, synchronized with your identity provider.
Data residency and sovereignty constraints must be embedded in the architecture. Operating in the EU means European customer data cannot be sent to an embedding model hosted in the US without explicit compliance assessment. Enterprise RAG architectures must support regional deployment with data routing logic that keeps data within its required jurisdiction.
Audit trails are non-negotiable in regulated industries. Every query, every retrieved document, every generated response must be logged with timestamp, user identity, and source citations. This is your legal defensibility layer and your continuous improvement mechanism.
The knowledge base requires active curation. A RAG system is only as good as what it can retrieve. Documents that are incorrect, superseded, or incomplete generate incorrect answers — confidently. Enterprise RAG requires a knowledge stewardship function: document owners who maintain quality, version control that retires outdated content, and monitoring that flags when retrieval quality degrades.
Common Pitfalls — And How to Avoid Them
Treating chunking as an afterthought. How you divide documents into chunks determines retrieval quality more than almost any other factor. Chunk at natural boundaries — paragraphs, sections, clauses. Use overlap. Test retrieval quality on real user queries before going to production.
Using the wrong embedding model for your domain. General-purpose embedding models underperform on specialized domains. Legal language, medical terminology, and engineering notation all benefit from domain-adapted embeddings. Evaluate multiple models on your actual data before committing.
Ignoring retrieval evaluation. Separate your evaluation — measure retrieval recall and precision independently from generation faithfulness. You cannot fix what you cannot measure.
Static knowledge bases. Your knowledge base will become stale the moment you stop actively ingesting new content. Build your ingestion pipeline before your retrieval layer. Define document ownership and update frequency for every source before going live.
What Parinamas Builds — And Why It Works
We implement enterprise RAG as a production system, not a proof of concept. Our implementations connect to your existing source systems: SAP, Salesforce, Workday, SharePoint, Confluence, ServiceNow, Snowflake, and custom internal systems. We enforce your access control model. We build your ingestion pipeline with real-time update handling. We implement retrieval evaluation from day one. We provide hallucination guardrails appropriate to your industry’s risk tolerance. And we transfer the knowledge to your team so you own what we build.
The 547% ROI we delivered for a manufacturing client was not a model selection decision. It was an architecture decision — eight specialized agents, each grounded in RAG, orchestrated to handle end-to-end workflows that previously required human coordination across multiple teams and systems. RAG was the foundation that made the agents reliable.
Enterprise AI that works is not about the model. It is about the data. RAG is the architecture that connects the two.
Start with our AI Readiness Assessment. In two weeks, you will have a clear picture of your AI maturity, your highest-value RAG opportunities, and a prioritized roadmap with real ROI projections.
Contact Parinamas to begin your AI Readiness Assessment →
Nahel Gandhi is the Founder & CEO of Parinamas, a Chicago-based AI enablement and digital transformation consultancy. Parinamas works with enterprises across financial services, manufacturing, logistics, retail, and food & beverage to implement production-grade AI systems that deliver measurable ROI.